


All of the Complexity and Diversity of Life is Coded with Just Four Letters
There’s something comforting about the elegance and simplicity of DNA: long strings of three-letter codes that provide all of the information necessary to create the proteins needed for life.
But our understanding of genetics, genes and how traits are passed from one generation to the next didn’t start with DNA. Instead, it started with a humble Austrian monk experimenting with the traits of pea plants in a monastery nearly 200 years ago. Since then, researchers discovered not only the structure of DNA, the molecule that makes up our genes, but the information coded in DNA to build the proteins of every organism on Earth.
Research is increasing our knowledge of genetics every day, revolutionizing medicine, agriculture and our understanding of the origins of human and other species. This article will provide an introduction to various topics in genetics, including the function of DNA, inheritance patterns, the Human Genome Project and how genetics is being used in our modern world.
What is Genetics?
Genetics is the study of genes, gene variation and how traits are inherited between parents and their offspring. Importantly, genetics is concerned with how DNA can create so much of the variation in people and organisms all around us.
Genetic research was in its infancy nearly two centuries ago, and knowledge of genes and the mechanism of inheritance has grown ever since. Gregor Mendel, an Austrian monk, first discovered the mechanism of trait inheritance in pea plants in 1865, but it wasn’t until 1944 that DNA was recognized as the hereditary material of life. In 1953, James Watson and Francis Crick discovered the three-dimensional structure of DNA. By 1966, the genetic code of DNA had finally been cracked.

By the 1990s, advances in DNA sequencing launched an exponential increase in genetic research. In 1990, the first breast cancer gene BRCA1 was mapped and the Human Genome Project, aimed at sequencing all 3 billion base pairs of the human genome, started in the U.S. In 2003, 13 years later, the Human Genome Project was finally completed.
Hereditary Versus Genetic Traits
One important distinction in genetic terminology is the difference between hereditary and genetic traits. While the terms can mean similar things in certain contexts, they are not interchangeable. Genetic refers to a condition that originates in a person’s genes. Hereditary traits, in contrast, are passed down from a biological parent to their child. Importantly, many genetic conditions are not hereditary, meaning the condition was not inherited by a child from their parents and instead arose independently in the child’s DNA at conception.
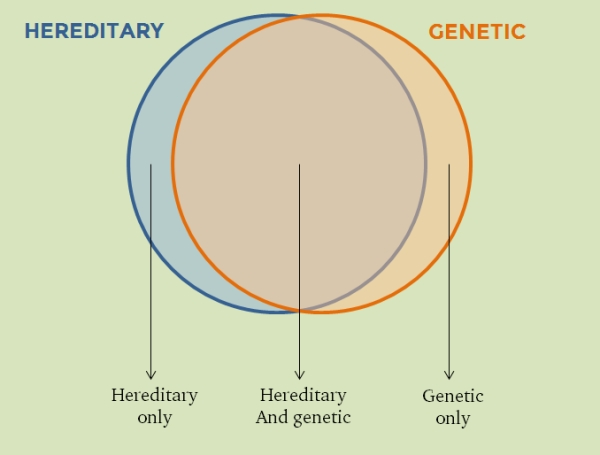
Many hereditary conditions also have a genetic component, in this case meaning the condition originated in a person’s inherited genes. However, the genetics of most hereditary conditions haven’t been established. Up to ten percent of some cancers are hereditary and the genetic cause, or etiology, can be identified, such as a specific mutation in a breast cancer gene. However, the exact genetic etiology of the vast majority of cancers, even in families with a strong history of the disease, cannot be identified at this time. This will change as research in cancer genetics progresses.
The Blueprint of Life: DNA Demystified
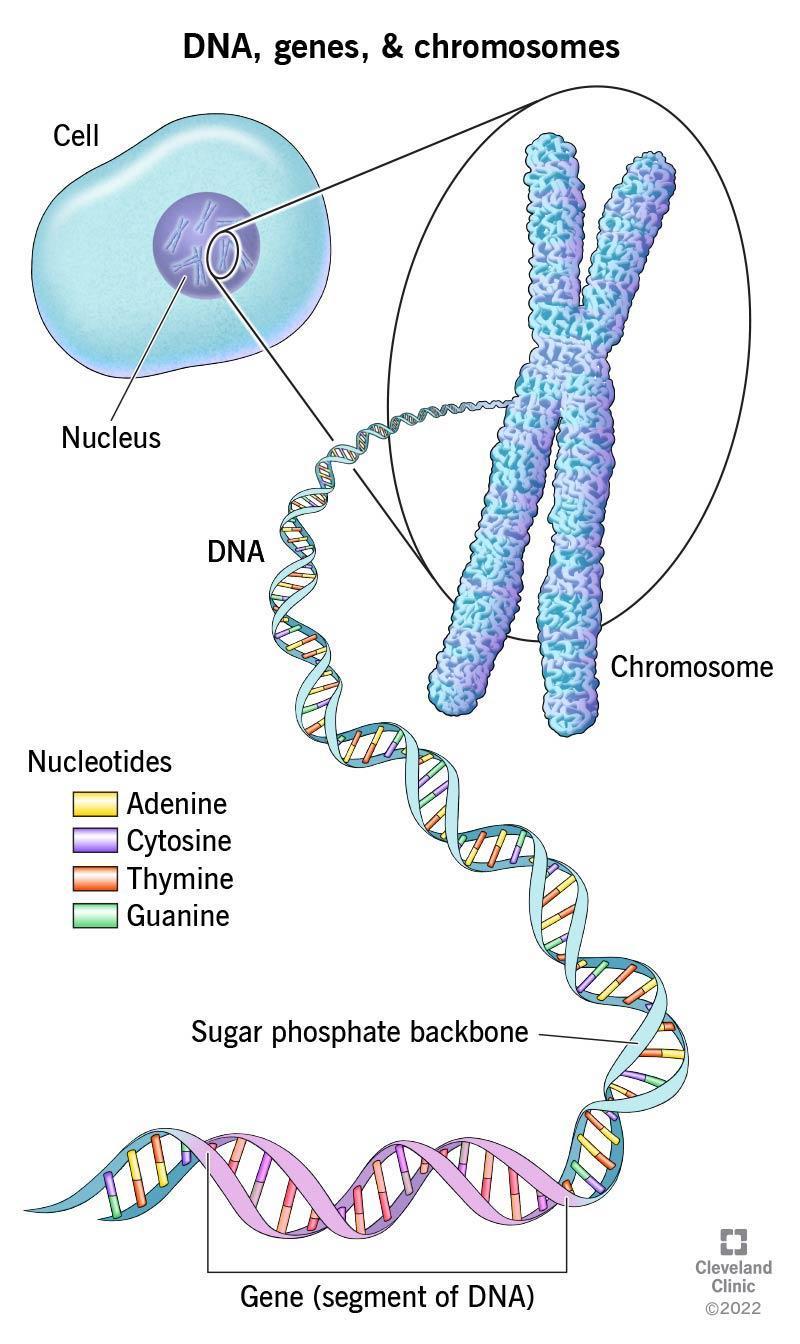
Genes are stretches of DNA that code for proteins in an organism, including humans. Human DNA is incredibly long (three billion base pairs) and is organized and tightly compacted into individual chromosomes in the nucleus of each cell. Some organisms only have a single chromosome, while some plants and single-celled protists have over 1,000. Humans have a total of 46 chromosomes, 23 from each parent.
DNA is a long, double-stranded, double-helix molecule. Importantly, the double-stranded nature of DNA makes it a stable molecule that is used as a repository of genetic information that can be copied to create proteins. DNA is made up of four different DNA bases, or “letters”: adenosine (A), cytosine (C), guanine (G) and thymine (T) that selectively bind one another across DNA strands. Adenosine binds to thymine (A→T) and cytosine binds to guanine (C→G).
You can think of DNA bases as the “alphabet” for the genetic code. The genetic code is made up of triplet codons, which are simply three-letter “words” that code for a specific amino acid, or building block, of a protein.
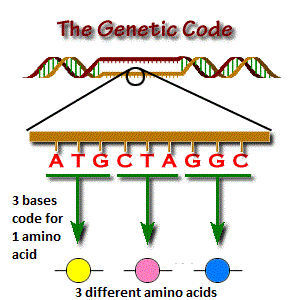
Every protein is made up of a string of 20 different amino acids that interact with one another to make incredibly complex three-dimensional shapes that interact with other molecules in the body. Proteins are the true workhorse of the cell, functioning as the structural components and enzymes necessary to facilitate all of the chemical reactions necessary to sustain life. In this way, our DNA codes for every protein in the body—one triplet codon at a time.
Understanding Inheritance: Mendelian Genetics
Gregor Mendel was an Austrian monk that performed some of the first genetic experiments with pea plants to determine how different traits, like flower and seed color, were passed down from one generation to the next. Mendel crossed garden pea plants with different characteristics and carefully observed what characteristics were present in the offspring. Mendel’s studies lasted from 1856 to 1863, through which he determined the first laws of inheritance, which are outlined below.
- The law of dominance is the first law of inheritance Mendel discovered. This law establishes the concept of dominant and recessive traits. Alleles, or gene variants, that determine a trait are considered dominant and alleles that are suppressed are recessive.
- The law of segregation explains that each individual has two alleles for each trait and that only one of those alleles is passed down to an individual’s offspring.
- The law of independent assortment establishes that the alleles for a gene are inherited independently of the alleles for other genes.
The concept of dominant and recessive alleles is easier to understand if you look at one of the experiments Mendel performed on his pea plants. Mendel wanted to understand what would happen if he crossed a pea plant with round seeds to a plant with wrinkled seeds. After he crossed the plants, all of the progeny, or offspring pea plants, had seeds that were round. In this case, Mendel discovered that the round seed allele (R) was dominant and the wrinkled seed allele (r) was recessive.
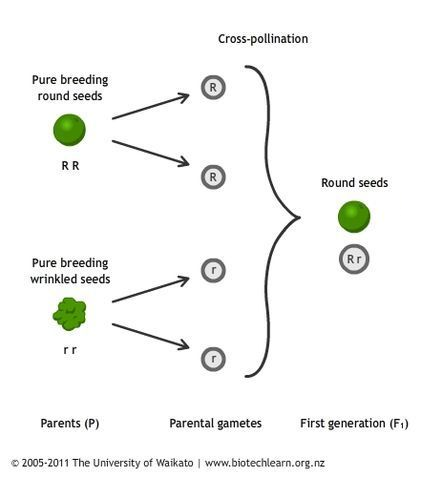
Each pea plant received one dominant round-seed allele, R, from the round-seed plant and one recessive wrinkled-seed allele, r, from the wrinkled-seed plant. This meant that the genotype of the progeny pea plants was Rr for every pea plant: each plant had one round-seed allele and one wrinkled-seed allele from each respective parent plant. The phenotype, or trait, of the progeny pea plant seeds was round. In this case, the round-seed allele, R, was dominant over the recessive wrinkled-seed allele, r, and the progeny seeds were round.
To make things a little more interesting, Mendel crossed the heterozygous, or having two different alleles, hybrid pea plant (Rr) offspring to each other to determine what traits the new progeny pea plants would possess. Each progeny pea plant, remember, has both one round-seed allele, R, and one wrinkled-seed allele, r. A tool called the Punnett square can help us better understand what happened to the sorting of alleles during pollination. The two alleles from each plant are organized on the top and the side of the Punnett square, respectively. The alleles from each parent plant are then added to each aligning square to establish the genotypes of the offspring pea plants.
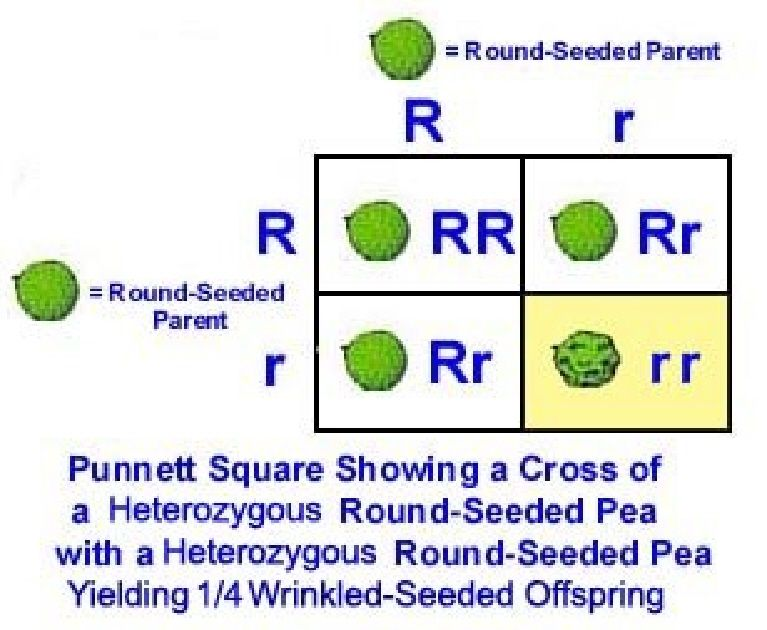
In his experiments, some of Mendel’s pea plants from the second cross had wrinkled seeds. The only way that this was possible was if the parent pea plants carried the recessive wrinkled (r) allele. In this way, one out of every four plants would receive two of the same recessive wrinkles alleles, the rr genotype, and the wrinkled seed phenotype. Genotypes that have two of the same allele are called homozygous. Half of the pea plants would receive one R allele and one r allele, an Rr genotype and the round seed phenotype, despite having the wrinkled (r) allele. One out of every four plants would also have two R alleles, the RR genotype and the round seed phenotype.
Alleles represent different variants of a gene, like round or wrinkled seeds, blue or green eyes or white or purple flowers. As our knowledge of genes and DNA has grown, we now understand that gene variants, or alleles, have different DNA sequences. Some of these more common variants are called single nucleotide polymorphisms, or SNPs.
A SNP is the change of a single nucleotide in a gene that is present in at least 1% of the general population. For each SNP, there can be up to four variations, one for each of the four nucleotides in human DNA: A,C,G or T. SNPs are common and are not considered disease-causing variants, or mutations. In contrast, rare and harmful BRCA1 or MSH6 variants are considered disease-causing mutations.
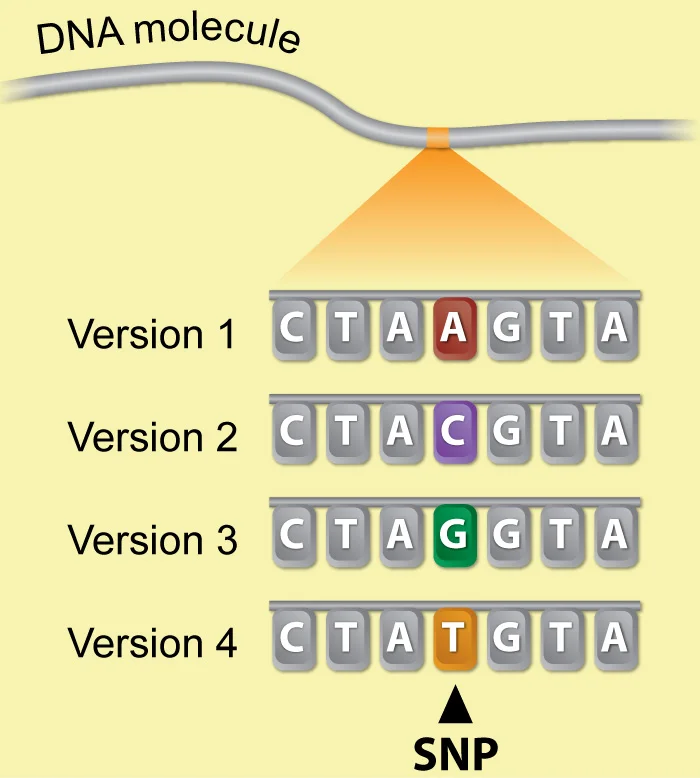
Each person has a few million SNPs and over 600 million different SNPs have been identified in populations across the world. Some SNPs are associated with an increased or decreased risk for disease, and there can be thousands of SNPs that affect a person’s risk of a single disease. Because of this, SNPs can be useful markers for determining the risk for common, complex diseases like autoimmune disorders, diabetes, heart disease and certain cancers.
Beyond Mendel: Exploring Complex Inheritance Patterns
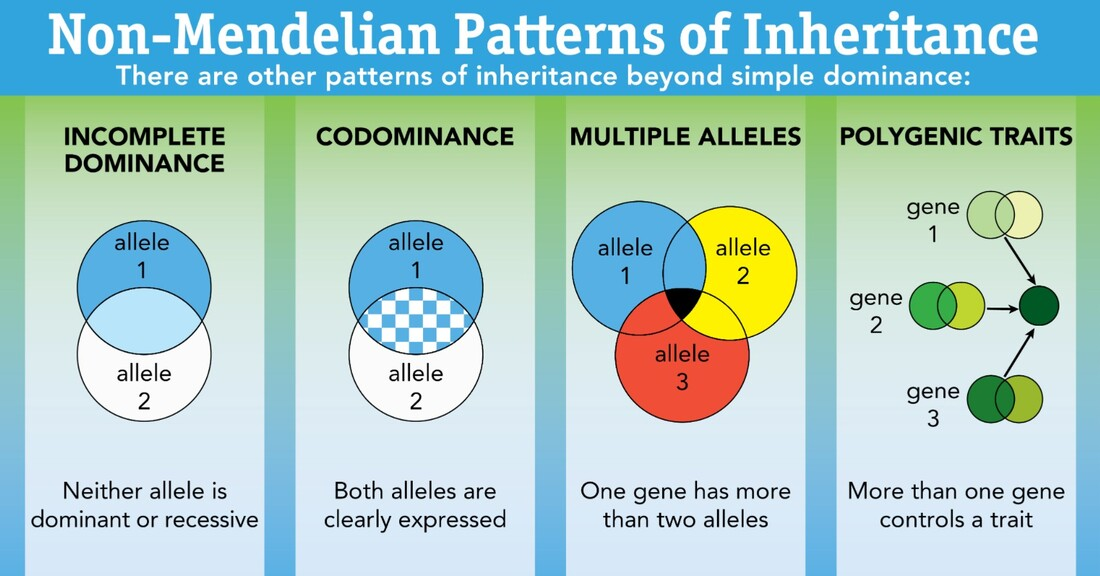
Mendel’s laws of inheritance represent the first set of rules characterizing how genes are passed on from one generation to the next, but they weren’t complete. It turns out that inheritance of traits doesn’t always follow these rules. These inheritance patterns are called non-Mendelian inheritance patterns, which are described in more detail below.
- Some traits are determined by more than one gene and are considered polygenic traits. An individual’s phenotype for that trait will depend on the complement of different alleles that individual inherits. Some examples of polygenic traits are height, eye color, and hair color.
- Traits can also be determined by more than two alleles, which are referred to as multiple alleles. Eye color, blood type (A, B, AB, O) and coat colors in rabbits are examples of traits with multiple alleles.
- Some alleles demonstrate incomplete dominance, meaning one allele is not fully repressed while the other is expressed. Instead, the alleles are expressed equally and produce a hybrid phenotype that combines both traits. Crossing a red flower with a yellow flower to create orange flowers is an example of incomplete dominance between alleles.
- Other alleles can also be expressed separately to create a new trait. This is called codominance. An example of codominant alleles are the AB blood type, where both the A-antigen allele and the B-antigen allele are expressed on every red blood cell, representing the AB blood type.
Importantly, the way in which alleles interact with one another affects an individual’s overall traits. In the case of traits like eye or hair color, these interactions affect a person’s appearance and little else. But for the many genes responsible for heart health, type-2 diabetes, arthritis or cancer, the interaction of alleles of many different genes can have an impact on more important traits that can affect overall health. Collectively, these variants of many different genes can affect an individual’s overall risk for disease — for better or for worse.
Our understanding of gene function and disease risk with specific alleles has increased exponentially in the past two decades. Today, individuals can be tested to determine their polygenic risk score (PRS) for specific diseases using both genetic and lifestyle information. The cumulative effect of all of these factors is used to determine an individual’s likelihood of developing a disease during a specific time period.
The PRS provided by Preciseli takes into account:
- The impact of thousands of SNPs (link to SNPs blog post)
- Lifestyle/environmental factors such as diet, exercise and sleep
- Established disease-causing genetic variants to provide patients with a risk figure for a specific disease.
Fortunately or unfortunately, PRSs are not set in stone. For example, an individual with a high PRS for coronary artery disease can lower their score with behavioral modifications, including diet, exercise and quality sleep. On the other hand, an individual with a low PRS for breast cancer could quickly increase their likelihood of developing disease by eating a poor diet and consuming too much alcohol. Importantly, PRSs are a useful, personalized tool that can provide individuals the data and motivation required to make healthy choices and protect their future quality of life.
Much of our current understanding of inherited disease risk comes from monogenic forms of disease, where a mutation or mutations in a single gene significantly increase an individual’s risk of developing a particular disease, including cancer or certain forms of heart disease.
Most humans have 23 pairs of chromosomes, or 46 chromosomes total. A chromosome is a segment of your genomic DNA that is condensed and wound around proteins. Each chromosome in a pair is inherited from a parent. Therefore, most humans receive two copies of a gene, one from each parent. As mentioned previously, variations in one or both copies of a gene can result in disease.
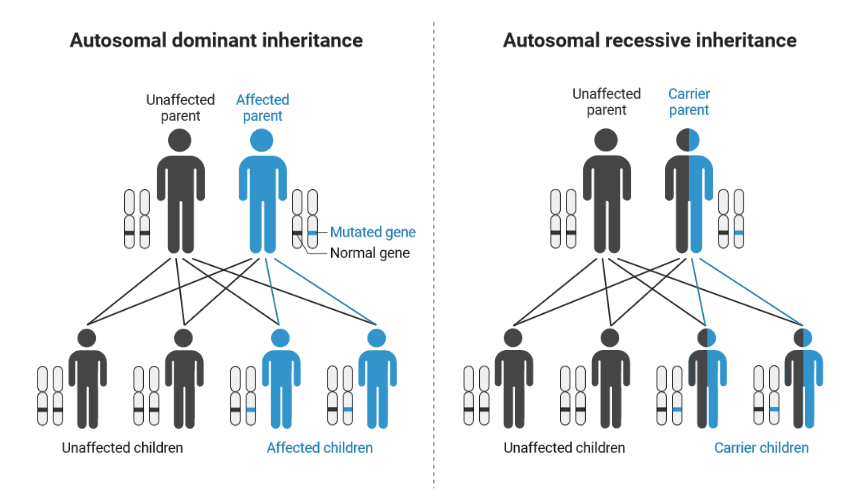
Two of the most common patterns of inheritance are autosomal dominant and autosomal recessive. “Autosomal” refers to the autosomes, or 44 chromosomes that are not the X or Y sex chromosomes. With an autosomal dominant disease, a person needs to possess only one abnormal copy of a gene to develop a disease. The BRCA1 and BRCA2 genes are good examples. If an individual inherits one abnormal copy of BRCA1 or BRCA2, they have hereditary breast and ovarian cancer (HBOC) syndrome and are at a much higher risk for developing certain cancers.
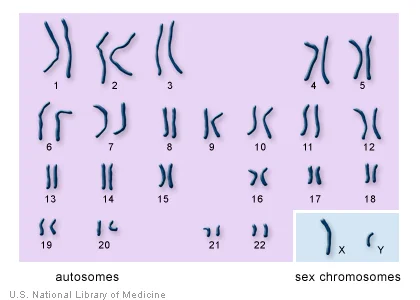
In contrast, the MSH3 gene is inherited in an autosomal recessive pattern, meaning a person needs two abnormal copies of a gene to develop disease. Harmful mutations in the MSH3 gene cause a cancer syndrome called MSH3-associated polyposis. To be affected with MSH3-associated polyposis, someone must inherit one abnormal copy of the MSH3 gene from each parent. The parents of this individual are both carriers of MSH3-associated polyposis, but the parents themselves are not affected by the disease. The children of parents that each carry an MSH3-associated polyposis allele have a one-in-four chance of inheriting both abnormal alleles from their parents and MSH3-associated polyposis.
The Human Genome Project and Its Impact
One of the early hurdles of genetic discovery was the difficult task of sequencing, or determining the DNA sequence, of the entire human genome. Forty years ago, scientists spent years sequencing relatively small regions of the genome. Today, the record for sequencing an entire human genome is five hours and two minutes.
Back in 1990, the U.S. government and other countries funded an ambitious project to sequence the entire human genome, made up of 3 billion base pairs of DNA, as a reference tool for future genetic study. The project took 13 years to complete, with some of the more difficult regions of the genome finally being sequenced as recently as 2022. The human genome sequence can be found on databases throughout the world, including GenBank, which is curated by the National Institutes of Health (NIH).
A sequenced human genome opened up a world of possibilities for genetic research, particularly in the study of genetic disorders. By comparing the genome sequences of people without disease to those with a particular disease, researchers were not only capable of identifying mutations responsible for genetic disorders but predicting the effects these mutations would have on protein production in individuals harboring the mutation.
The completed human genome additionally created new opportunities for personalized medicine that simply weren’t possible without comprehensive DNA information. Researchers began identifying genes responsible for breaking down medications and how variants of these genes could affect how a person responds to different drugs. Additionally, hereditary disease research tied specific monogenic mutations to an increased risk for diseases such as breast cancer and heart disease, allowing patients with mutations to be screened and treated proactively for disease based on their unique risk. Personalized medicine has also extended to PRSs to determine inherited risk of disease based on common genetic variants.
With all of the advancements in DNA technology and genetic research, ethical considerations for human well-being and the well-being of other organisms is paramount. The Genetic Information Nondiscrimination Act (GINA) is a federal law put in place to protect people from genetic discrimination in their employment and health insurance coverage. Importantly, no protections are currently afforded for genetic discrimination in the determination of life, long-term care or disability insurance. For GMOs, it is important for researchers to carefully consider the effects of genetic engineering on the well-being of both the organism and the environment.
Genetics in the Modern World
As a reference tool, a sequenced human genome has allowed scientists to hone in on monogenic mutations that increase the odds of disease, improve forensic DNA analysis, more accurately predict the effects of medications, determine the effects of common DNA variants on the development of disease, genetically engineer pest-resistant crops and much, much more.
The genomes of many other organisms have also been sequenced, allowing researchers to determine the function of more genes and engineer organisms that contain special traits through genetic engineering. Today, genetically modified organisms (GMOs), particularly crops, are commonplace and benefit society in a variety of ways.
- Most corn in the U.S. is genetically modified for pest resistance and herbicide resistance, producing more resilient crops with higher yields. Bt corn is genetically engineered corn that produces naturally occurring proteins from the bacteria Bacillus thuringiensis that kill certain insect pests but don’t harm humans, pets, livestock, other animals or beneficial insects like ladybugs. This genetic modification allows more corn to be produced while using less insecticides.
- GMO cotton was created to provide resistance to bollworms, improving crop yield.
- Some GMO potatoes were genetically engineered for pest resistance, while others were created to resist bruising and browning during transport to supermarkets.
- GMO alfalfa, which is primarily used to feed cattle, is engineered to resist the effects of herbicides, improving crop yield and the nutritional quality of the feed.

The goal of genetic research is to improve health and prevent disease, and genetics has succeeded in both of these areas. Future genetic research will continue to personalize medicine, improving in both disease detection and disease treatment. DNA sequencing already allows individuals to assess their genetic risk for disease through monogenic mutations and polygenic risk scoring, and additional research will only improve the accuracy of these assessments. Genetic testing of various cancers, for example, will also personalize disease treatment to improve patient outcomes.
While genetics can seem overwhelmingly complicated and confusing at times, it’s helpful to remember that all of the complexity, diversity and beauty we see in the living world is coded by four simple letters. Living organisms have millions of genetic variations and mutations that account for so much of the diversity we see between individuals and are critical for survival. As humans, we have the opportunity to decipher that code to improve our lives in ways never before possible, which is a truly wondrous and beautiful thing.

